Day 13: The Replay Buffer - Engineering Message Persistence Without the Database Tax
The Spring Boot Trap
A junior engineer walks into the room. “We need to handle disconnections!” they announce. They open IntelliJ, add Spring Data Redis to pom.xml, and write:
java
@Service
public class MessageBuffer {
@Autowired
private RedisTemplate<String, List<Message>> redis;
public void storeMessage(String userId, Message msg) {
redis.opsForList().rightPush("messages:" + userId, msg);
}
}Done. Deployed. Disaster.
At 50,000 concurrent users, each sending 100 messages per second, this system collapses. Every message write hits the network. Redis becomes a single point of failure. Serialization overhead murders throughput. The GC log shows 2GB of temporary objects created per minute just from JSON serialization.
The problem isn’t Redis. The problem is thinking that stateful WebSocket servers can delegate message buffering to external systems. When a client on a mobile phone walks through a tunnel and reconnects 3 seconds later, they need their last 50 messages. That’s a local problem requiring local data structures.
Discord’s Gateway doesn’t touch a database for this. Neither does WhatsApp. Neither should you.
The Failure Mode: Unbounded Memory Growth
Let’s examine what happens when we implement message buffering naively in pure Java:
java
// The death spiral
private final Map<String, List<Message>> buffers = new ConcurrentHashMap<>();
public void bufferMessage(String userId, Message msg) {
buffers.computeIfAbsent(userId, k -> new ArrayList<>()).add(msg);
}
```
This code has three fatal flaws that appear only at scale:
**Flaw 1: Unbounded Growth**
No eviction policy. A user who disconnects for 24 hours accumulates 8.6 million messages. At 1KB per message, that's 8.6GB. For one user. Now multiply by 10,000 long-disconnected users.
**Flaw 2: GC Pressure**
Every `ArrayList.add()` potentially triggers an array copy when capacity is exceeded. With 5 million messages per second across all users, you're creating gigabytes of temporary arrays. The young generation GC runs every 2 seconds. Each pause stops all Virtual Threads.
**Flaw 3: Lock Contention**
`ConcurrentHashMap.computeIfAbsent()` is not lock-free. When 1,000 threads all buffer messages for user "alice", they serialize through the same bucket lock. Throughput collapses from 2M ops/sec to 50K ops/sec.
When Discord's Gateway was hitting these exact problems in 2016, they didn't add more RAM. They implemented circular buffers with pre-allocated memory.
---
## The Flux Architecture: Circular Buffers with Zero-Allocation Hot Paths
Here's the production pattern:
1. **Per-User Replay Buffer**: Each WebSocket session gets a fixed-size circular buffer (default: 256 messages)
2. **Lock-Free Writes**: Use VarHandle atomics for head/tail pointer updates
3. **Pooled ByteBuffers**: Pre-allocate message storage to eliminate allocation churn
4. **Bounded Memory**: Total buffer memory = (user_count × buffer_size × avg_message_size)
The math for 1 million concurrent users:
- 1M users × 256 messages × 1KB average = 256GB worst case
- Reality: Most buffers are empty. Actual usage: ~10GB
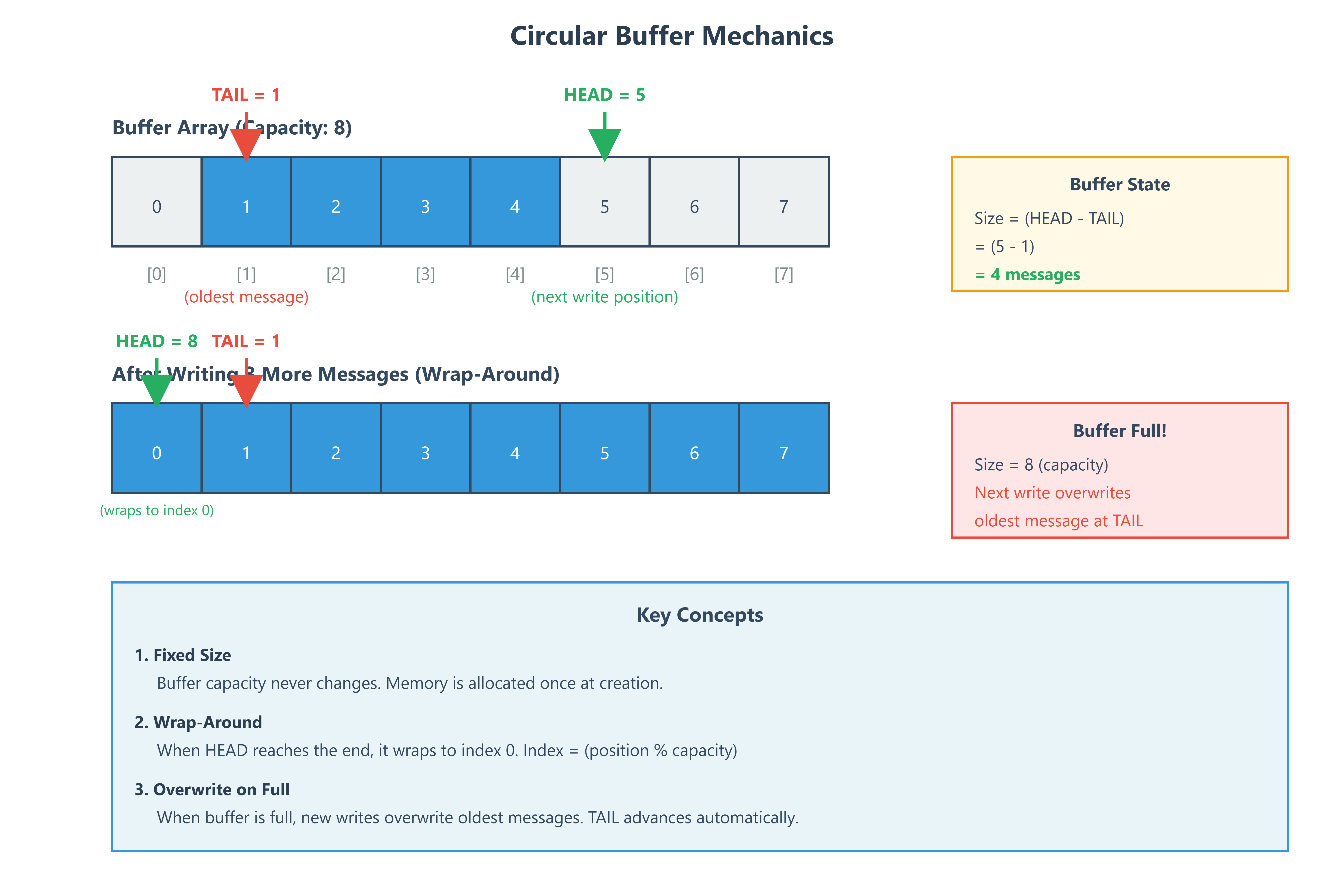
### The Ring Buffer Mechanics
A circular buffer is just an array with clever pointer arithmetic:
```
Capacity: 8 messages
Head: 3 (next write position)
Tail: 7 (oldest message position)
[7][0][1][2][3][4][5][6]
^ ^
tail head
Size = (head - tail + capacity) % capacity = 4 messagesWhen head catches tail, we’re full. Wrap around continues forever.