Day 36: The Hot Partition Problem
Why Storing All Channel Messages in One Row Destroys Your Database
The “Just Use Cassandra” Trap
A junior engineer reads that Discord uses Cassandra for message storage. They open the DataStax documentation, see a simple example with a
messagestable, and write this schema:
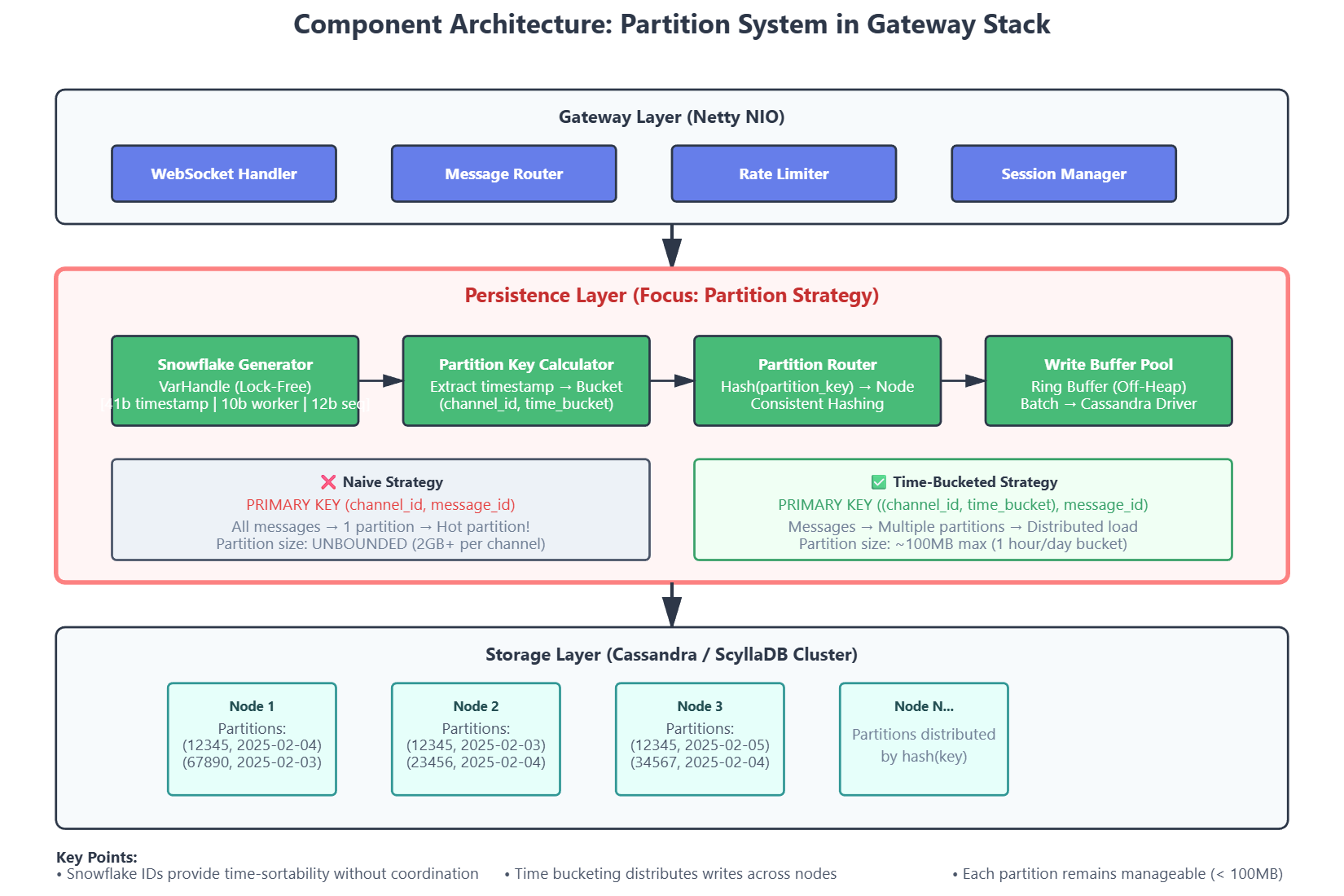
CREATE TABLE messages (
channel_id bigint,
message_id bigint,
content text,
author_id bigint,
timestamp bigint,
PRIMARY KEY (channel_id, message_id)
);
They test it locally with 1,000 messages. Query latency is 2ms. They ship it to production. Three weeks later, during a major announcement in your
#generalchannel (50,000 active users), the Cassandra cluster starts returning timeouts. You SSH into the coordinator node and see:
WARN: Partition messages/12345 size 2.1GB exceeds recommended 100MB
ERROR: Compaction of messages-Data.db abandoned after 6 hours
The database is melting. The “simple” primary key
(channel_id)has created a hot partition - a single logical row that has grown so massive it can no longer be managed by the storage engine. This is the tax you pay for not understanding LSM-tree data modeling.
The Failure Mode: When One Partition Becomes a Black Hole
Cassandra (and ScyllaDB) are wide-column stores built on Log-Structured Merge Trees. Unlike B-Tree SQL databases that update in-place, LSM trees append immutable SSTables to disk, then periodically compact them. The primary key structure defines the partition key (which node stores the data) and clustering columns (how data is sorted within the partition).
In our naive schema:
channel_idis the partition keymessage_idis the clustering column
This means ALL messages for channel 12345 live in ONE partition on ONE node. Here’s why this destroys performance:
1. Memory Pressure During Reads
When you query SELECT * FROM messages WHERE channel_id = 12345 LIMIT 50, Cassandra must:
Load the partition’s Bloom filter into memory
Deserialize the SSTable index for that partition
Scan through potentially gigabytes of data to find the latest 50 messages
If the partition spans 10 SSTables (each 200MB), the read path must merge-sort across all of them. On a busy channel, this causes heap allocation spikes that trigger Stop-The-World GC pauses.
2. Write Amplification via Compaction
As the partition grows, compaction becomes catastrophic. A single partition’s data might be spread across:
5 SSTables in L0 (uncompacted, just flushed from memtable)
3 SSTables in L1
1 massive SSTable in L2
When compaction runs, it must read ALL these SSTables, merge them, and write a new compacted SSTable. For a 2GB partition, this means:
Reading 2GB from disk
Decompressing/deserializing
Merging sorted sequences
Writing 2GB back to disk
This process can take hours and blocks other operations on that partition. Meanwhile, new writes keep appending to memtables, creating more L0 SSTables. You enter a compaction death spiral where compaction can’t keep up with writes.
3. Coordinator Node Overload
In Cassandra’s ring architecture, one node acts as the coordinator for each partition based on the hash of the partition key. For channel_id = 12345, that hash might map to Node 3. Now:
Every write to channel 12345 goes to Node 3
Every read from channel 12345 goes to Node 3
Node 3’s CPU, disk I/O, and network are saturated
If channel 12345 is your #general with 100k messages/hour, Node 3 becomes a bottleneck while Nodes 1, 2, 4-10 sit idle. You cannot horizontally scale because the partition is the atomic unit of distribution.
4. Tombstone Accumulation
When users delete messages, Cassandra doesn’t remove data immediately - it writes a tombstone marker. These accumulate in the partition until compaction. A partition with 1 million messages and 200k deletions now has 1.2 million entries, making scans even slower. During reads, Cassandra must filter out tombstones, which consumes CPU and causes GC pressure.