Day 39: Cursor-Based Pagination
Seeking Through Billions of Messages
The “Spring Boot Data” Trap
Let’s say you’re building a chat app and need to show message history. A typical approach using Spring Data Cassandra might look like this:
@Repository
interface MessageRepository extends CassandraRepository<Message, UUID> {
Page<Message> findByChannelId(UUID channelId, Pageable pageable);
}
// Controller
@GetMapping("/messages")
Page<Message> getMessages(@RequestParam UUID channelId, @RequestParam int page) {
return messageRepo.findByChannelId(channelId, PageRequest.of(page, 50));
}
```
This code looks clean and simple. But there’s a massive problem hiding underneath that only shows up when you scale to real-world usage.
What goes wrong:
The OFFSET Illusion - When someone requests page 200 (which means showing messages 9,950-10,000), Spring translates this into fetching ALL 10,000 rows from Cassandra, then throwing away the first 9,950. Imagine downloading an entire textbook just to read one page.
Materialization Spike - The
Page<T>object loads every single message into a Java List in memory before returning anything. With thousands of concurrent users, your server runs out of heap space.State Inconsistency - Between loading page 5 and page 6, new messages arrive. Now page 6 shows some messages you already saw on page 5 (duplicates), or skips messages entirely.
No Streaming - Everything gets buffered in memory before being converted to JSON, which means even more heap pressure.
At scale (100,000 users scrolling through chat history), this causes 15-second garbage collection pauses where your entire server freezes.
The Failure Mode: Offset-Based Pagination Death Spiral
To understand why this fails, we need to look at how Cassandra actually stores data. It’s fundamentally different from SQL databases.
Cassandra organizes messages like this: ``` Partition Key: channel_id = “general-chat” ├─ Clustering Key: message_id = 1234567890 (timestamp-sorted) │ └─ {author_id, content, timestamp} ├─ Clustering Key: message_id = 1234567891 └─ … (millions more in sorted order on disk)
The Partition Key groups related data together (all messages in one channel). The Clustering Key determines the sort order within that partition (newer messages have higher IDs).
When you query with OFFSET:
sql
SELECT * FROM messages
WHERE channel_id = ?
LIMIT 50
OFFSET 10000Here’s what happens behind the scenes:
Cassandra Scans Anyway - Internally reads 10,050 rows from disk (because clustering keys are physically sorted)
Network Transfer - Sends all 10,050 rows over the network to your Java driver
Driver Buffering - Creates 10,050 Java
Messageobjects in heap memoryDiscard 99.5% - Immediately throws away 10,000 objects, triggering garbage collection
The Real Cost at Scale:
Channel with 10 million messages: Loading page 1000 requires scanning 50,000 rows
1000 concurrent users paginating: 50 million row scans per second
JVM heap pressure: 200 MB/second allocation rate (each Message ~4 KB)
Result: Old Generation garbage collection fills up, causing 10-second “stop-the-world” pauses where nothing works
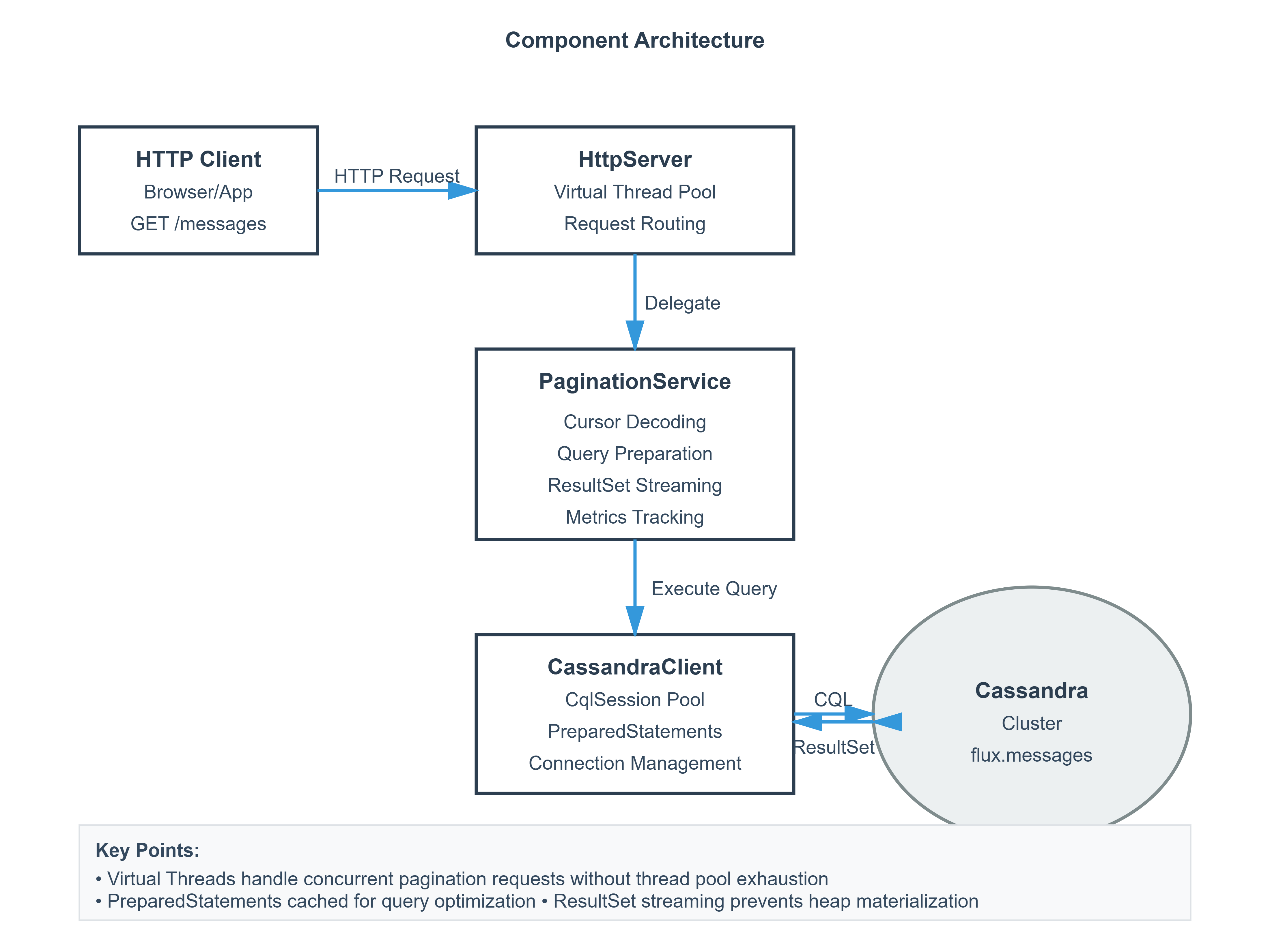
The Flux Architecture: Cursor-Based Seeking with Snowflake IDs
The production solution Discord and other major chat platforms use:
Client State (Opaque Cursor):
cursor = base64(message_id:1234567890|timestamp:2025-02-07T10:00:00Z)
Server Query (Stateless Seeking):
SELECT * FROM messages
WHERE channel_id = ?
AND message_id < 1234567890 -- Resume exactly where we left off
ORDER BY message_id DESC
LIMIT 50
Why This Works:
Clustering Key Efficiency - Cassandra stores messages sorted by
message_idon disk, so seeking to a specific ID is extremely fast (like using an index in a book)Range Scan - The query becomes: “Start at message 1234567890, read backwards 50 rows.” No wasted scanning.
Zero Server State - The cursor is entirely managed by the client (like a bookmark). The server doesn’t need to remember where each user is.
Streaming Iteration - We never load the full result set into memory. We process one row at a time.
Snowflake ID Structure (64-bit Long): ``` |-- 41 bits: Timestamp (milliseconds since epoch) |-- 10 bits: Data center ID |-- 12 bits: Sequence number (4096 IDs per millisecond)
This gives us:
Time-sortable - Newer messages automatically have higher IDs
Globally unique - No collisions across distributed servers
Indexable - Cassandra stores Longs efficiently (8 bytes vs 36 bytes for UUID strings)