Day 41: Time-Window Compaction Strategy - Why Discord Doesn’t Rewrite History
The Spring Boot Trap
A junior engineer building a chat application typically reaches for familiar tools:
java
@Entity
public class Message {
@Id @GeneratedValue
private Long id;
private String content;
private Timestamp createdAt;
}
@Repository
public interface MessageRepository extends JpaRepository<Message, Long> {
List<Message> findByChannelIdOrderByCreatedAtDesc(Long channelId, Pageable pageable);
}
```This works beautifully in development. JPA handles the SQL, the B-Tree index on created_at makes queries fast, and everything feels “production-ready.” Ship it!
Then reality hits at scale:
Day 30: Your database is handling 1 million messages/day (11.5 writes/second). PostgreSQL’s B-Tree keeps rebalancing as new rows insert. Write latency spikes to 50ms during rebalancing.
Day 90: 90 million messages stored. The B-Tree index is now 3GB and doesn’t fit in RAM. Every query requires disk seeks. P99 latency is 500ms.
Day 180: Your retention policy deletes messages older than 30 days.
DELETE FROM messages WHERE created_at < NOW() - INTERVAL '30 days'runs for 6 hours, locking the table and causing an outage.
The fundamental problem: B-Trees optimize for reads (O(log N) seeks), but chat logs are write-heavy (99% writes, 1% reads). Every insert requires updating the index structure, and bulk deletes require rewriting pages.
The Failure Mode: Write Amplification in B-Trees
When you insert a message into a B-Tree:
Find the correct leaf page (may require 3-4 disk seeks for a large tree)
Insert the row (may trigger a page split if full, cascading up the tree)
Update secondary indexes (
channel_id,user_id)Write transaction log (WAL) for crash recovery
One logical write becomes 10+ physical writes. This is called write amplification, and it destroys performance for write-heavy workloads.
When you delete old messages:
Mark rows as deleted (more writes!)
PostgreSQL’s MVCC keeps old versions until VACUUM runs
VACUUM rewrites entire pages to reclaim space (hours of I/O)
Discord learned this the hard way. In 2017, they were using MongoDB (which uses B-Trees under WiredTiger) and hit a wall at 100M messages/day. Switching to Cassandra (LSM trees) dropped write latency from 50ms to 5ms and made deletions instant.
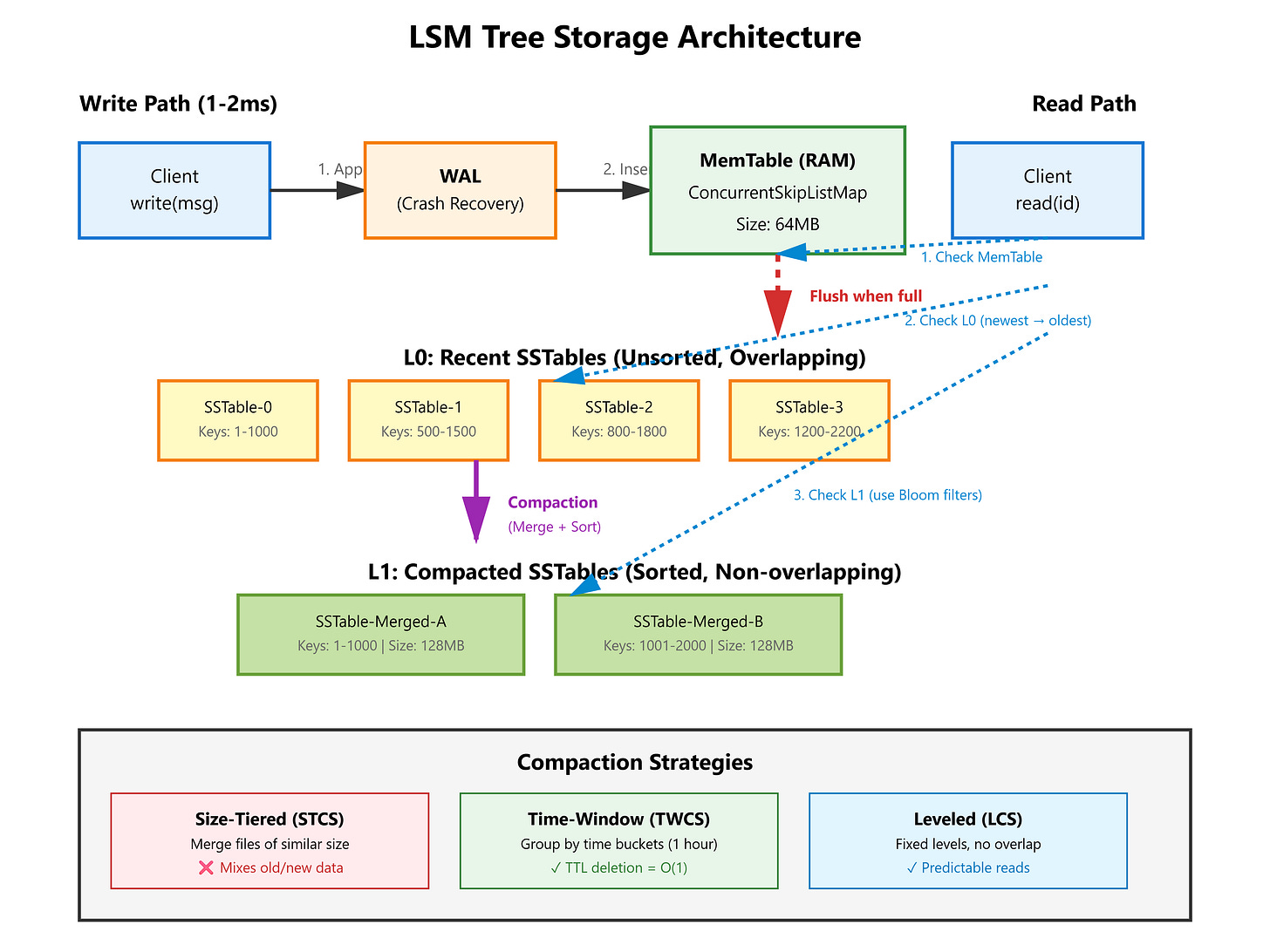
The Flux Architecture: Log-Structured Merge Trees
LSM trees invert the B-Tree model: optimize for writes, pay the cost on reads.
Core insight: Treat storage as an append-only log. Never update data in place.
[MemTable (RAM)] → Flush → [SSTable 1] [SSTable 2] [SSTable 3] ... (Disk)
↓ Compaction merges overlapping SSTables
[Merged SSTable]
Write path (latency: ~1ms):
Insert into in-memory sorted structure (MemTable) - a ConcurrentSkipListMap in Java
Append to Write-Ahead Log (WAL) on disk for crash recovery
Done! No index updates, no page splits.
Read path (latency: ~10ms):
Check MemTable first (recent data)
Check SSTables from newest to oldest (each is sorted)
Merge results (a message may exist in multiple files if updated)
Compaction (background process):
Periodically merges overlapping SSTables into larger, sorted files
Removes deleted data (tombstones)
This is where the strategy (STCS vs TWCS) matters