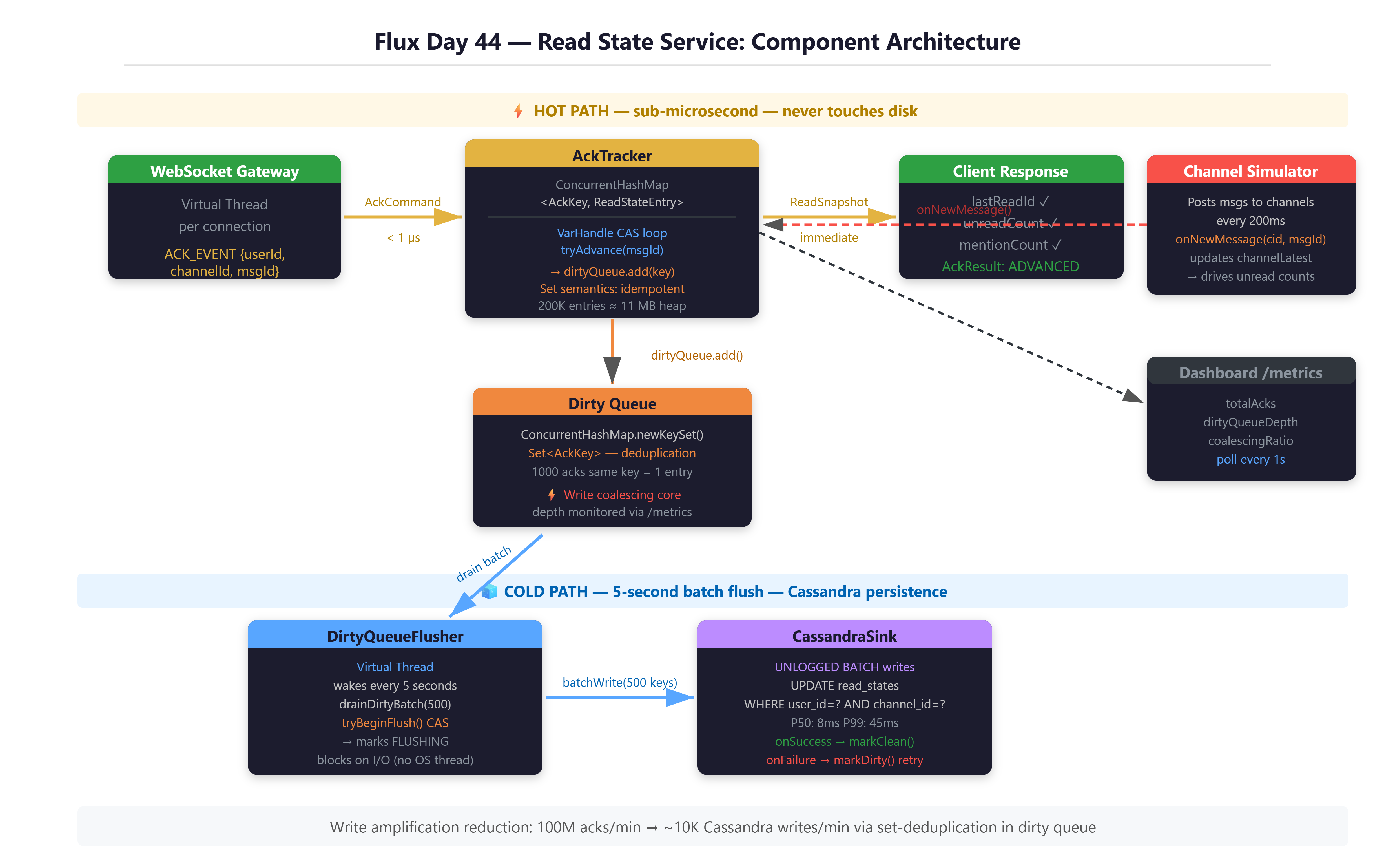
What You Will Build
By the end of this lesson, you will have a working, production-modeled Ack Tracking System — the engine that powers Discord’s unread message indicators. It implements a two-tier write architecture that compresses millions of acknowledgments into thousands of database writes using write coalescing, monotonic CAS-based state advancement, and a Virtual Thread background flusher.
This is not a toy. The patterns here are the same ones production teams use when they realize their SQL database is on fire.
Learning Objectives
After completing this lesson, you should be able to:
Explain why a SQL
UPDATEapproach collapses under write-heavy read state workloadsImplement a lock-free, monotonically advancing read pointer using
VarHandleCAS loopsBuild a write-coalescing dirty queue using
ConcurrentHashMap.newKeySet()and explain why set semantics are the key insightMeasure coalescing ratio and recognize what a healthy vs. degraded ratio looks like in production
Articulate why Virtual Threads are the right primitive for the background flusher — not
ExecutorService
Part 1 — The Problem
The Spring Boot Trap
A junior engineer handed the unread markers ticket will immediately open spring-data-jpa. They build something like this:
@Entity
public class ReadState {
@Id @GeneratedValue private Long id;
private Long userId;
private Long channelId;
@Column(name = "last_read_message_id")
private Long lastReadMessageId;
private int mentionCount;
}
@Transactional
public void ack(long userId, long channelId, long messageId) {
var state = repo.findByUserIdAndChannelId(userId, channelId)
.orElseGet(() -> new ReadState(userId, channelId, 0L));
state.setLastReadMessageId(messageId);
repo.save(state);
}
It passes all tests. The PR gets approved. It deploys to staging with 50 concurrent users and nobody notices the bomb ticking inside it.
The problem isn’t the logic. The problem is the throughput contract — a SQL UPDATE involves acquiring a row lock, writing to the B-Tree leaf page, updating the index entry, appending to the WAL, and releasing the lock. That’s four to six I/O-equivalent operations per ack, sequentialized through the row lock. You cannot parallelize them for the same (user_id, channel_id) pair. And you will have many concurrent acks for the same pair — your user is on their phone, their laptop, and their tablet simultaneously.
The Failure Mode: Write Amplification Hell
Let’s do the math that Discord’s engineers had to do:
10 million active users × 10 channel acks per minute = 100 million writes per minute
PostgreSQL write throughput ceiling (8-core RDS): ~50,000 writes/sec = 3 million writes/minute
You are 33 times over the ceiling before you’ve written a single optimization
The B-Tree makes this worse. Every write to a hot (user_id, channel_id) index causes page-level contention. Under write bursts — like when 50,000 users simultaneously open the app after a major announcement — the B-Tree’s internal nodes experience cascading page splits. PostgreSQL responds with table-level lock escalation. Your read latency spikes from 2ms to 4,000ms. Your application’s connection pool exhausts. Your load balancer starts returning 503s. Your SREs call this a write amplification thundering herd.
The second failure vector is on the application side. A naive in-memory cache of (userId, channelId) → Long seems attractive at first glance. Run the numbers: 100 million users × 500 channels average × 8 bytes per Long object header plus value = approximately 2.4 terabytes of live object graph on heap. Your G1GC regions are full before the JVM finishes initializing. The stop-the-world pause for a single major collection will clock in at 90+ seconds. Your WebSocket connections will time out. The core issue is boxing overhead — every Long in a HashMap is a heap object with a 16-byte object header plus 8 bytes of actual data. That is three times the memory needed.