Day 45: Centralized Log Management - Your Distributed System’s Black Box
Why Netflix Engineers Can Debug 1000+ Services in Minutes
When a critical payment processing task failed at 3 AM across Stripe’s distributed scheduler fleet, engineers didn’t scramble through individual server logs. They opened one dashboard, typed a transaction ID, and instantly saw the complete story across 47 different service instances. Within 8 minutes, they identified a database connection timeout pattern and deployed a fix.
This isn’t magic—it’s centralized log management. Today, we’re building your scheduler’s “flight recorder” that makes debugging distributed systems feel like solving a puzzle with all pieces visible.
The Distributed Logging Problem: Finding a Needle in 50 Haystacks
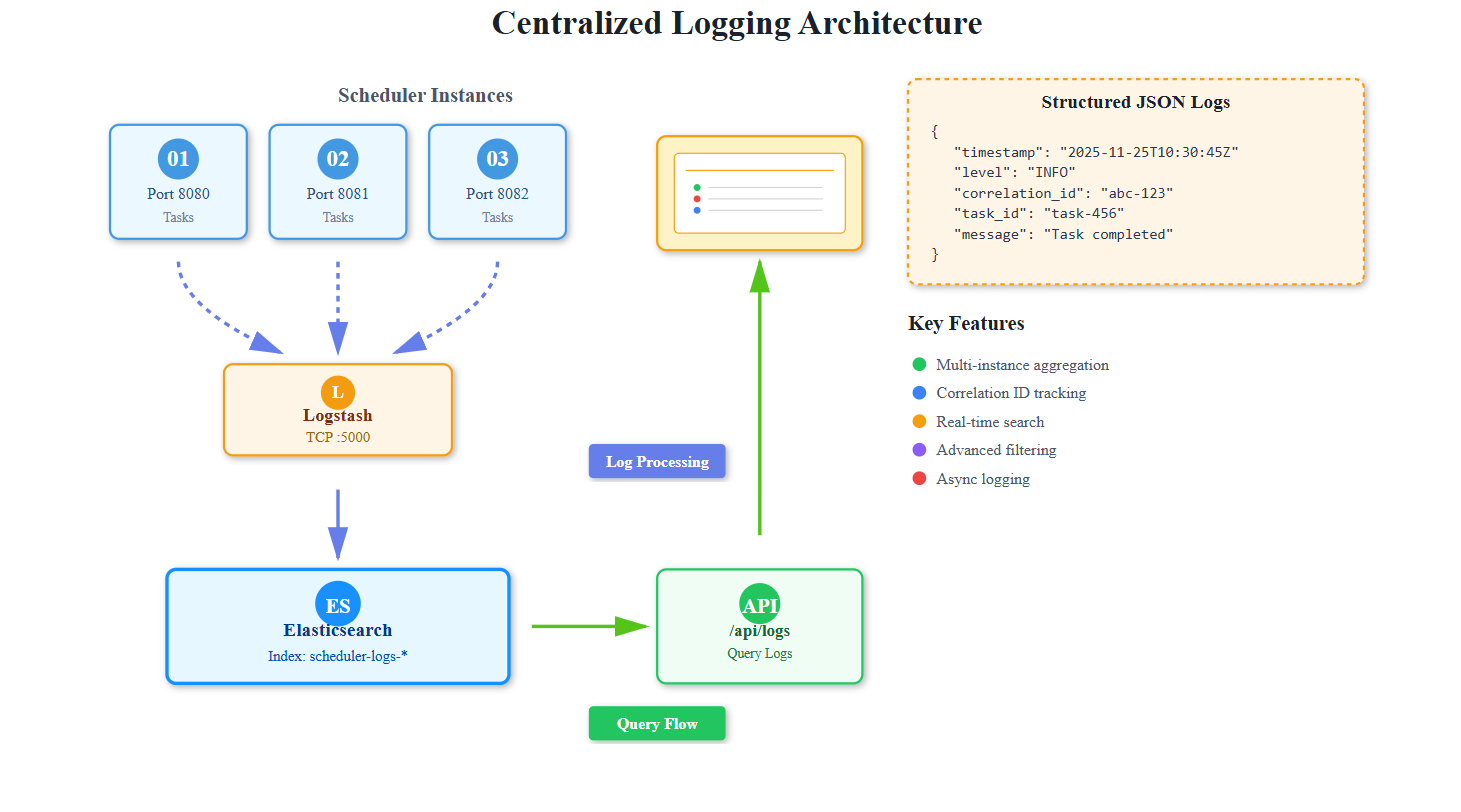
Imagine you’re running 20 task scheduler instances. A user reports: “My daily report task failed yesterday.” Now what?
Without centralized logging:
SSH into 20 different servers
Search through 20 different log files
Try to piece together timestamps across time zones
Miss the critical error because it happened on instance #17
Spend 2 hours finding what should take 2 minutes
With centralized logging:
Open one browser tab
Search for task ID or user identifier
See the complete timeline across all instances
Identify the exact failure point instantly
Fix it in minutes, not hours
This is why companies like Uber, Airbnb, and DoorDash treat centralized logging as non-negotiable infrastructure.
What We’re Building: Your Scheduler’s Mission Control
Today’s implementation creates a production-grade logging system that:
Captures structured logs from multiple scheduler instances in JSON format
Aggregates everything into Elasticsearch for lightning-fast searches
Provides real-time visibility through a modern web dashboard
Enables powerful queries like “Show me all failed tasks from user X in the last hour”
Correlates distributed traces so you can follow a task’s journey across instances
Think of it as giving your distributed scheduler a unified nervous system where every instance reports what it’s doing, and you have a control center to observe everything.